

1 Staying Grounded in DBMS Principles
1.1 Cost-Efficiency: The Essential Value of DBMS
A Database Management System (DBMS) is a software layer that manages the storage, organization, access, and manipulation of data. While its core functionality may evolve with technological advances in the past decades, the essential value of a DBMS or data service delivery remains unchanged: cost efficiency and service resilience that consistently underpin business success.
Cost-efficiency as one of the most critical values a DBMS offers to business, the ability to manage and process data without excessive resource consumption directly impacts a company’s bottom line. A cost-efficient DBMS minimizes hardware and operational overhead, reduces licensing and maintenance expenses, and optimizes energy usage. This allows businesses to scale their data operations without proportionally scaling their costs.
In competitive industries, where margins are often tight, a DBMS that delivers high performance with minimal resource waste becomes a strategic asset—freeing up capital and talent to focus on innovation, customer service, or market expansion. From our perspective, a successful DBMS product should anytime remain anchored in its essential values, especially customer's TCO (total cost of ownership), regardless of how IT architecture or technology trends evolve.
1.2 Relational Data Still Dominates the Core of Business
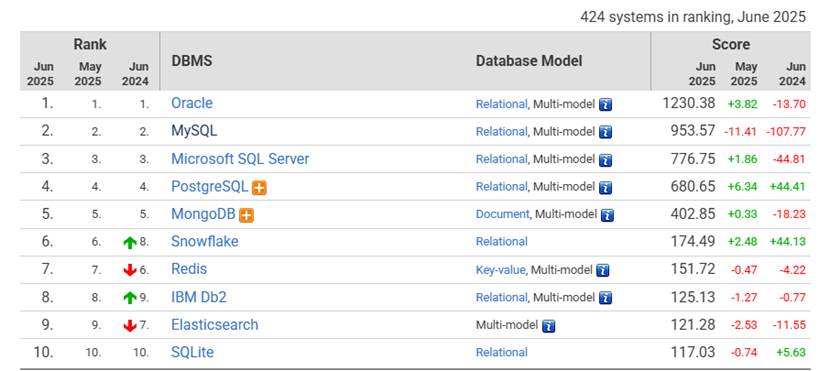
Figure 1. Popularity of database engines, relational DBMS dominates
(sourced from https://db-engines.com/en/ranking )
Relational data continues to dominate core business logic because it aligns naturally with how organizations model and enforce real world rules and relationships. Business operations are inherently structured and interrelated. The relational model, with its schema enforcement, foreign key constraints, and ACID-compliant transactions, offers a reliable and expressive way to represent this complexity.
Moreover, SQL remains a universal language for querying and manipulating structured data, supported by a mature ecosystem of tools and integrations. This consistency enables clear business rules, reliable reporting, and maintainable systems across departments and industries. Even as newer paradigms like NoSQL, graph, and time-series databases gain traction for specific workloads, relational databases remain the default for mission-critical applications—where data consistency, integrity, and logic enforcement are non-negotiable.
1.3 Higher Expectations in the Age of AI and Green Computation
Even in the AI era that began accelerating in 2022, the Database Management System (DBMS) remains a critical foundation—and is becoming even more essential to the success of modern AI applications. First, the functional correctness and execution efficiency provided by a DBMS kernel represent decades of academic and industrial refinement. These systems are built upon foundational innovations such as the relational model, ACID-compliant concurrency control, and query optimization. Modern AI applications increasingly rely on these strengths and expect the DBMS to handle the data layer robustly, without any intention of replacing it with alternatives. Second, the rise of AI-specific computations, especially those involving tensor operations, has created demand for deeper integration of vector management features within the DBMS kernel itself.
Beyond growing functional expectations, cost-efficiency is becoming an increasingly critical priority for DBMSs. This is largely driven by the shift toward more simplified and flexible delivery models—such as serverless architectures—and the rise of modern AI applications that operate autonomously across multiple layers of the technology stack. In this context, the automated deployment and scaling of DBMS instances is expected to surge, fueled by both AI-driven infrastructure management and the global push for green, resource-efficient computing.
1.4 Conclusion
Database Management Systems (DBMSs) have been a foundational layer of enterprise computing for over half a century. As AI applications continue to evolve, DBMSs are not being replaced—in fact, they are more critical than ever. Modern systems demand not only advanced data management functionality but also flexible service delivery and strong cost-efficiency.
At PhoebeDB, we are building a new-generation, relational data–centric DBMS designed to meet these rising expectations. By anchoring our product in the enduring values, we aim to provide customers with a highly cost-effective backend solution for their modern IT architecture, optimized for both traditional workloads and AI-era demands.
2 Emerging of Next Generation DBMS
2.1 Modern Hardware: A Shift in Compute Characteristics
Compared with hardware IT solutions used 50 years ago, key hardware components have been greatly improved due to the technical evolution and revolutions. Here we discuss single server’s hardware evolutions:
Massive CPU Parallelism. Unlike in the past, when a server typically had fewer than 10 cores, modern servers can now scale their parallel computing capacity significantly. This is enabled by multi-socket designs using NUMA (Non-Uniform Memory Access) architecture, which allows multiple CPU chips to operate cohesively. At the same time, the number of physical cores per CPU chip has increased rapidly, with some chips now exceeding 100 cores, greatly enhancing on-chip parallelism. As a result, the original motivation for using multi-server clusters to expand a system’s computation capacity is, in many cases, no longer as compelling.
Large and cost friendly DRAM. The cost per gigabyte of DRAM has dropped significantly, making hundreds of gigabytes to terabyte-level memory a standard configuration in modern servers. As a result, for many typical workloads, the majority of online production data can now reside in DRAM rather than on disk. Since data transfer between CPU and DRAM is vastly faster than between DRAM and disk, computations are far less likely to stall due to traditional I/O latency bottlenecks. This shift prompts us to rethink performance optimization priorities—moving the focus from disk I/O latency to CPU-DRAM access latency.
High bandwidth and low latency I/O. Mechanical hard drives used to be the only affordable solution for enterprise customers to store online production data, but they suffered from high latency during I/O operations. This limitation heavily influenced classic DBMS designs, which focused on hiding I/O latency across the entire data access path. With the advent of semiconductor-based SSDs, I/O latency has been drastically reduced, and random I/O is no longer a major bottleneck. Today, mainstream NVMe SSDs communicate with DRAM over high-speed PCIe buses, further narrowing the performance gap. As a result, traditional strategies like well tuned caching page data in DRAM have become less critical. Moreover, numerous studies have shown that classic DBMS caching algorithms often fail to fully exploit the bandwidth and parallelism offered by modern I/O subsystems, highlighting the need for new optimization approaches.
2.2 Memory-centric DBMS Design Philosophy
The 2008 paper "OLTP Through the Looking Glass, and What We Found There" highlighted the mismatch between classic DBMS implementations and modern hardware characteristics and proposed a new DBMS design philosophy based on a detailed analysis of OLTP transaction costs.
By analyzing the component-level costs of a typical TPC-C NewOrder transaction, the paper revealed that only 6.8% of execution instructions is spent on useful computation. As shown in Figure 2, the majority of the cost is attributed to maintaining functional correctness and other overheads.
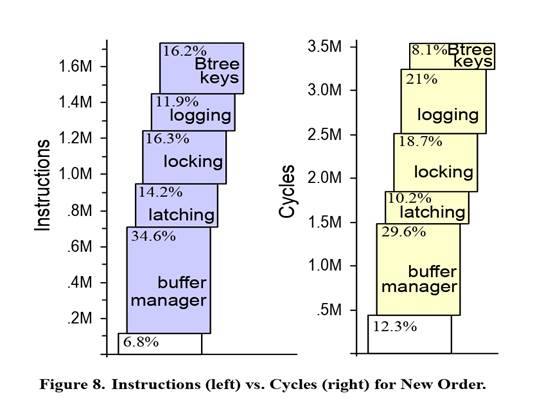
Figure 2 Instructions and cycles for New Order Transaction in Paper " “OLTP Through the Looking Glass, and What We Found There” "
The paper demonstrated that by eliminating unnecessary overhead from critical execution paths—through the use of modern algorithms and data structures—it is possible to achieve over a 10× improvement in OLTP throughput.
Consequently, in 2013, " “Anti-Caching: A New Approach to Database Management System Architecture” " introduced Anti-Cache as an experimental implementation of this emerging DBMS design philosophy—one that focuses on optimizing computation around in-memory data. In this architecture, massive parallel processing is fully leveraged to serve workloads directly from production data residing in DRAM, minimizing reliance on slower storage layers.
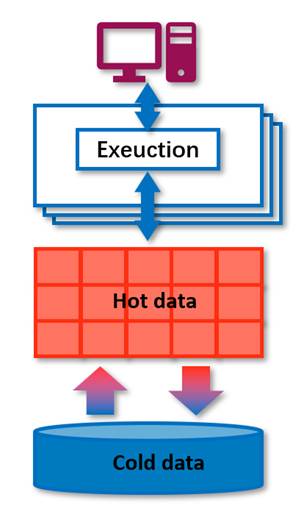
Figure 3.Design philosophy of DBMS architecture
While Anti-Cache was proposed in 2013, efforts to explore this new architecture began as early as 2008. Over nearly two decades, numerous experimental systems have been designed to pursue major performance breakthroughs by fully leveraging modern hardware capabilities. These efforts have demonstrated that disk-based DBMSs can achieve performance levels comparable to in-memory systems. PhoebeDB is now being developed to bring these innovations into industrial practice, following a path shaped by recent advances in both academic research and pioneering industry work.
2.3 All-in-One Kernel for Cost-Efficiency
The development of specialized DBMS products has always been driven by the pursuit of optimal cost-efficiency—aligning workload requirements with the lowest possible cost. In the evolution of DBMS architecture, for example, a key motivation behind the proposal of MPP architecture data warehouse was the practical need for real-world users to store and process large volumes of historical data using affordable commodity hardware.
Consequently, internet companies, as pioneers, introduced numerous new DBMS projects. These systems were not designed to offer comprehensive functionality; instead, they focused on meeting a few extreme internet style workload requirements within tight budget constraints. This represents an extreme example of using striped-down implementation to achieve cost-efficiency.
However, most customers with limited professional software engineering capabilities face significant challenges when using specialized DBMS products. Building IT solutions with such backends increases the complexity of integrating and managing heterogeneous platforms and often results in reduced efficiency and resilience due to data movement across multiple data stores. Even in modern cloud applications—where a simplified consumption model can mask some of this complexity—the additional effort still incurs costs, ultimately reflected in the overall service fees of the solution.
As a result, the value of all-in-one DBMS kernel, while long recognized, remained unrealized due to past hardware technology limitations and the lack of corresponding algorithm inventions. Today, with the evolution of modern hardware, the capabilities of a single server have grown dramatically. By fully harnessing these advancements, a unified kernel that supports multi-model and hybrid data workloads can now operate with far greater efficiency, allowing the vision of an all-in-one DBMS to be practically realized in real-world customer scenarios.
2.4 Cost-Efficiency: Starting from Single Server Again
First of all, the single-server DBMS kernel represents the simplest and most fundamental implementation of a database system. Virtually all distributed and cloud-native DBMS architectures are technical evolutions derived from this core. In this sense, the single-server kernel defines the upper bound of cost-efficiency, serving as the performance and efficiency baseline from which more complex, distributed solutions must scale.
On the other hand, modern servers can scale up significantly in both compute and storage capacity, and this upward trend shows no clear limits in the foreseeable future. As a result, the motivation to adopt distributed solutions solely to increase system volume is becoming less compelling in many real-world scenarios. In fact, a single-server architecture paired with a primary-standby high availability (HA) setup now meets the needs of more use cases, often delivering a much better total cost of ownership (TCO) compared to distributed systems.
Therefore, PhoebeDB is currently focused on delivering cost-efficiency and positions itself as a next-generation DBMS, starting by achieving a breakthrough in single-server kernel performance.
3 What is PhoebeDB
PhoebeDB is a relational data-centric multi-model DBMS engineered for AI era, delivering world-leading hybrid performance access both transactions and analytics workloads. Its fully redesigned native HTAP kernel leverages cutting-edge technologies, while maintaining seamless compatibility with the PostgreSQL ecosystem.
PhoebeDB is now under construction aiming to provide following key features to landing product values:
3.1 World-leading OLTP performance.
PhoebeDB completely re-implements its storage and runtime layers to fully harness the capabilities of modern hardware, particularly by unlocking parallel computation among multiple CPU cores and maximizing the I/O bandwidth of NVMe SSDs through PCIe. Rather than sacrificing standard features, PhoebeDB achieves high OLTP performance through a tenfold increase in computational efficiency.
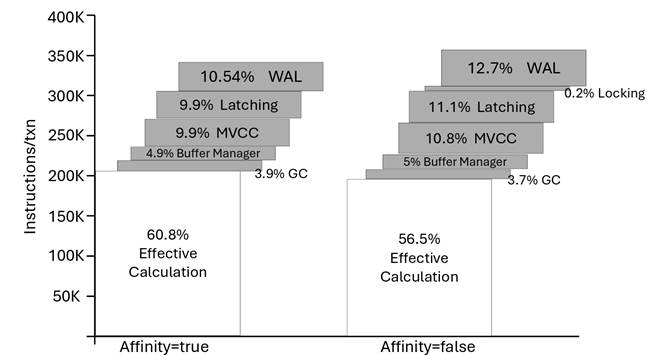
Figure 4. Breakdown of Instruction Count per Transaction for PhoebeDB from TPC-C
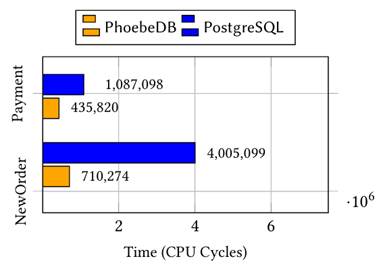
Figure 5. Runtime level transaction processing time
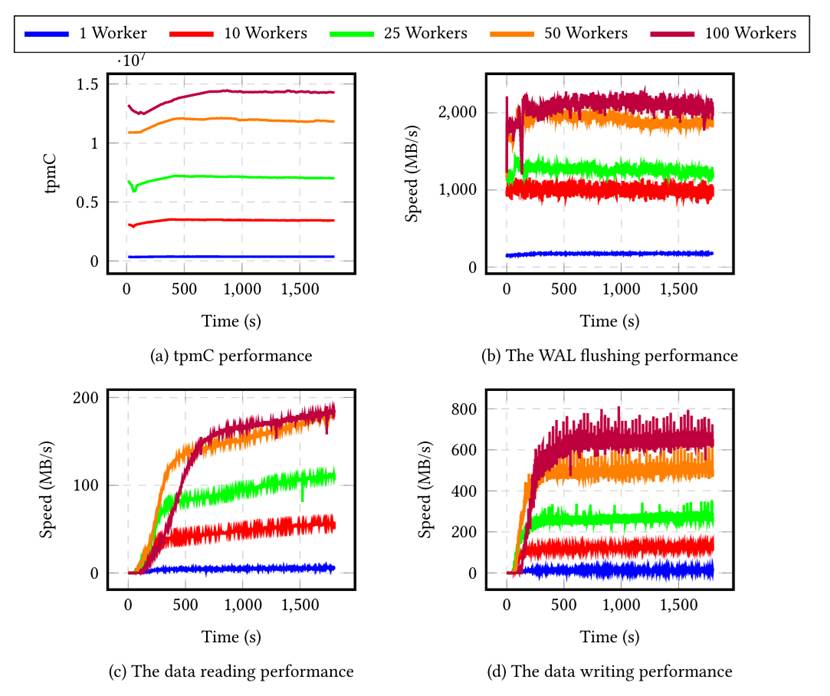
Figure 6. TPC-C performance comparison varying numbers of workers
As detailed in paper “PhoebeDB: A Disk-Based RDBMS Kernel for High-Performance and Cost-Effective OLTP” (2025), PhoebeDB raises effective computation utilization from 6.8% to 60.8% (Figure 4). Within the runtime component , the user-defined function implementing the NewOrder transaction executes 6 times faster than PostgreSQL 17 (Figure 5). This paper demonstrates PhoebeDB’s first milestone in full functional storage layer OLTP throughput, achieving 13.7 million tpmC on the TPC-C benchmark (Figure 6).
This level of throughput was attained not with top-of-the-line hardware or specialized hardware, but on a mid-tier server configuration using only standard, general-purpose components:
- Two Intel(R) Xeon(R) Gold 5320 CPUs (2021 release, 2.2 GHz base frequency, 52 physical cores, 104 virtual cores)
- 512 GB of DRAM
- 2 Samsung PM9A3 Enterprise NVMe SSDs (2021 release)
- CentOS 9 as installed OS version.
By calculating transaction cost based on the concept defined in official TPC-C specification, using PhoebeDB can very promisingly achieve single server end-to-end 10 million tpmC throughput and reduce the transaction cost lower than 0.1 CNY per tpmC comparing with current lowest record 0.85CNY per tpmC from official report at TPC-C Details
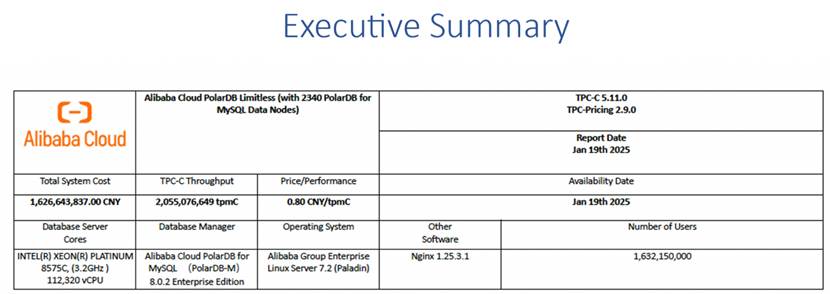
Figure 7. Top TPC-C record’s Price/Performance record
3.2 Native HTAP with top OLAP performance.
Current mainstream HTAP engines support hybrid workloads through in-kernel isolation mechanisms to meet OLAP performance goals; however:
A.Using an OLAP-focused data copy for analytics is not an ideal HTAP solution. Current HTAP engines often rely on a separate OLAP-optimized copy to achieve strong analytical performance, but this approach comes with several unavoidable technical drawbacks:
- Data replication process means data freshness problem. OLAP purposed copy always has a time lag comparing with latest OLTP production data.
- Data replication process slows down OLTP throughput, as the copying is integrated into the OLTP system’s data computation pipeline. Even when executed asynchronously, replication must be kept reasonably up to date to avoid significant data freshness issues. As a result, OLTP performance is still constrained by the progress of data copy maintenance. In other words, slowing down OLTP throughput is a balancing solution to hide data freshness problem on analytical side.
- OLAP-focused data duplication imposes a constant load on system resources, preventing adaptive allocation and degrading efficiency.
B.Integrating OLAP-optimized SIMD and OLTP-optimized scalar runtimes within a single HTAP DBMS kernel leads to architectural inefficiencies. Without a unified storage format at the storage layer, the runtime must be expanded to accommodate differing input formats and computation patterns, increasing complexity and overhead.
- Traditional interpreted execution incurs higher framework overhead. Each runtime operator consumes and produces different in-memory tuple formats, requiring additional effort to handle data transport and format conversion between operators.
- Developing equivalent operator logic for multiple input/output formats poses significant engineering challenges. A DBMS kernel demands the highest levels of execution performance and functional reliability. In an industrial-grade product, maintaining multiple low-level implementations for the same function set significantly increases complexity and multiplies the risk of quality and stability issues.
PhoebeDB aims to deliver a true native HTAP DBMS kernel defined as one copy of data supports tenfold fast OLTP throughput and top-tier real-time OLAP performance. The highlighted values to the user briefly are:
- High performance OLTP for cost-effective production system;
- High OLAP performance on up to date production data (true real-time) for industry top-tier cost-effective business intelligence and batch processing solution;
- Zero tuning and maintenance cost.
As detailed in “PhoebeDB: A Disk-Based RDBMS Kernel for High-Performance and Cost-Effective OLTP” (2025), unlike the traditional approach of using row-store formats to maximize OLTP performance, PhoebeDB adopts a PAX-format storage layer and still successfully achieves a throughput record of 13.7 million tpmC with one moderate configured server. This demonstrates that PhoebeDB has effectively unified its storage format, laying a solid foundation for building a native HTAP engine in the future.
As the next step toward delivering native HTAP with optimal performance, PhoebeDB will introduce:
- Temperature-aware autonomous PAX storage, enabling HTAP workloads with minimal tuning and maintenance.
- JIT runtime, designed for maximum CPU cache efficiency and minimal framework overhead, ensuring the best computational performance.
- Intelligent workload scheduling, which guarantees the QoS of high-value OLTP transactions while dynamically utilizing idle resources for OLAP analytics.
3.3 Full PostgreSQL Compatibility.
PostgreSQL is a mature, stable and extensible RDBMS that leads the relational database market in transactional workloads. PhoebeDB fully embraces its rich ecosystem, including its extensive plugin support.
At the SQL interface level, PhoebeDB delivers native HTAP storage and runtime capabilities seamlessly through PostgreSQL’s standard interface, ensuring minimal usage barriers. In addition to providing specialized HTAP functionality, PhoebeDB also focuses on accelerating the performance of high-value PostgreSQL plugins—without altering their external interfaces or behavior.
3.4 Relational Data-Centric Multi-Model Engine.
As discussed above, since relational data forms the foundation of most application backends, and OLTP-first HTAP performance is more critical in real-world customer scenarios, PhoebeDB defines its core value around cost-efficiency—delivered firstly through its native HTAP capabilities for relational workloads.
Beyond native HTAP, PhoebeDB recognizes the diversity of real-world data, and leverages PostgreSQL’s extensibility to support multi-model data and hybrid workloads. Driven by the goal of delivering the most cost-effective data backend, PhoebeDB’s multi-model support offers serval key benefits:
- Simplify data architecture by managing multiple data models within a single unified kernel.
- Improved computation efficiency through reduced data duplications and minimized consistency overhead.
- Accelerated development and delivery with minimal learning curve and no need for specialized knowledge.
3.5 Serverless.
As the natural evolution of cloud computing: removing complexity, maximizing cost-efficiency, and enabling extreme agility, especially considering modern application architecture in this epic AI era, serverless is a modern and widely adopted way of delivering value to customers. PhoebeDB also provides data services in a serverless mode to fit the trend in the future.
4 PhoebeDB’s Value Delivery: Cost-efficiency Centric
PhoebeDB recognizes the transformative impact of cloud computing and the shift in application delivery in the current AI-driven era. It affirms that the fundamental values traditionally provided by DBMS, such as structured data management, consistency, and reliability, continue to play a central role in the architecture of modern applications and LLM-powered AI solutions.
PhoebeDB is being built to be the most cost-effective data backend for modern workloads. To achieve this, it delivers value across the following dimensions:
- High hardware efficiency. Maximizing computation throughput to reduce hardware, energy, and maintenance costs.
- Native high-performance HTAP. Enabling simplified data backends for structured, transaction-analytical hybrid workloads.
- Multi-model kernel. Streamlining data management for modern AI applications that involve diverse data types.
- Serverless and elastic resource scaling. Offering a flexible and efficient consumption model that aligns with dynamic workload demands.
- Full support for the PostgreSQL ecosystem. Minimizing the cost of software migration and reducing the learning curve for development and maintenance teams.
- No specialized hardware. Eliminating the risk of provider lock-in and long-term cost exposure.
